Blog
-
Duke CE LeadershipLearning Tree International
From Innovative Ideas to Breakthrough Impact
-
AI Artificial Intelligence Machine LearningLearning Tree International
Demystifying AI: A Beginner's Guide to Artificial Intelligence (AI)
-
Prince2 AgileLearning Tree International
PRINCE2 Agile v2: What’s New and Why It Matters
-
AgilePMLearning Tree International
AgilePM v3 Is Here: What You Need to Know
-
Advanced Leadership Certificate Program Duke CELearning Tree International
How to Thrive During Change - Lead with Confidence in Uncertain Times
-
Advanced Leadership Certificate Program Duke CELearning Tree International
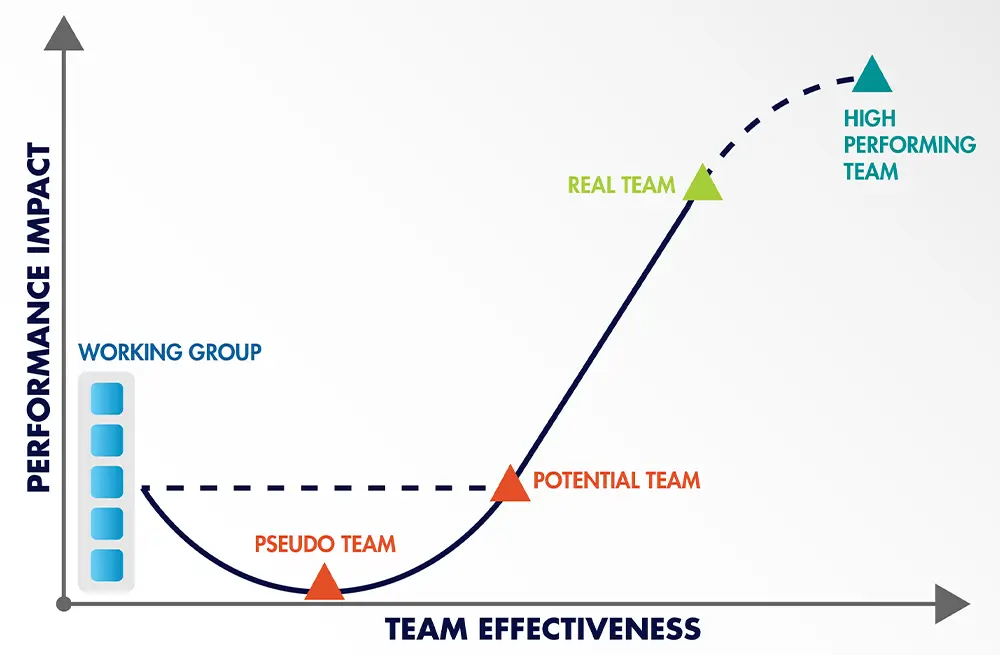
Elevate Your Team's Impact - How Strong Team Dynamics Drives Business Success
-
Artificial Intelligence Copilot Microsoft 365Learning Tree International
Boost SMB Productivity with Microsoft 365 Copilot
-
ITIL ITSM Service DeskLearning Tree International
Mastering the ITIL Certification Pathway for a Successful IT Career
-
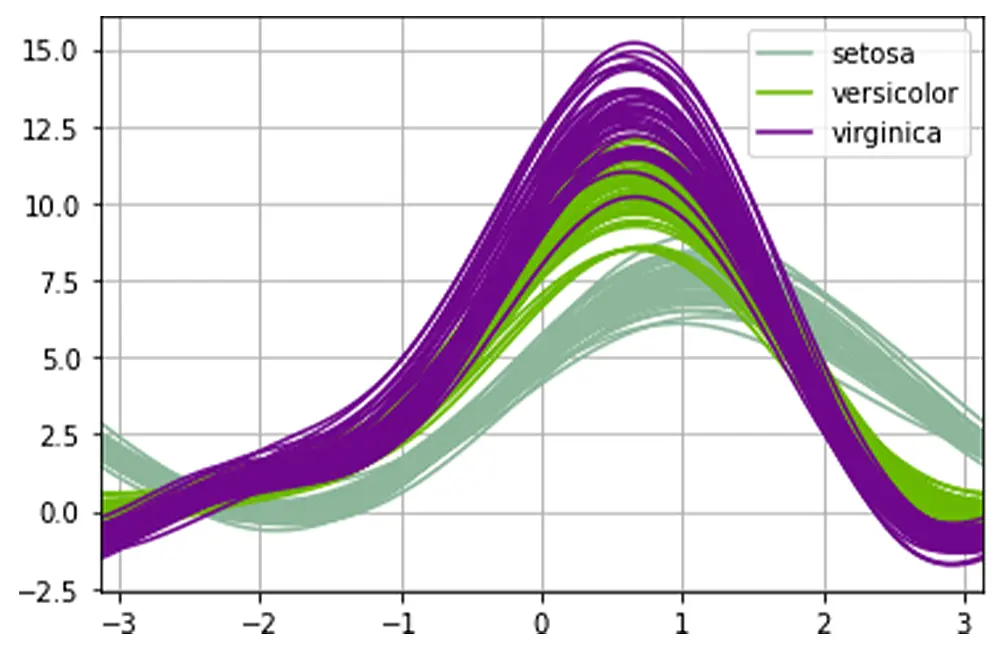
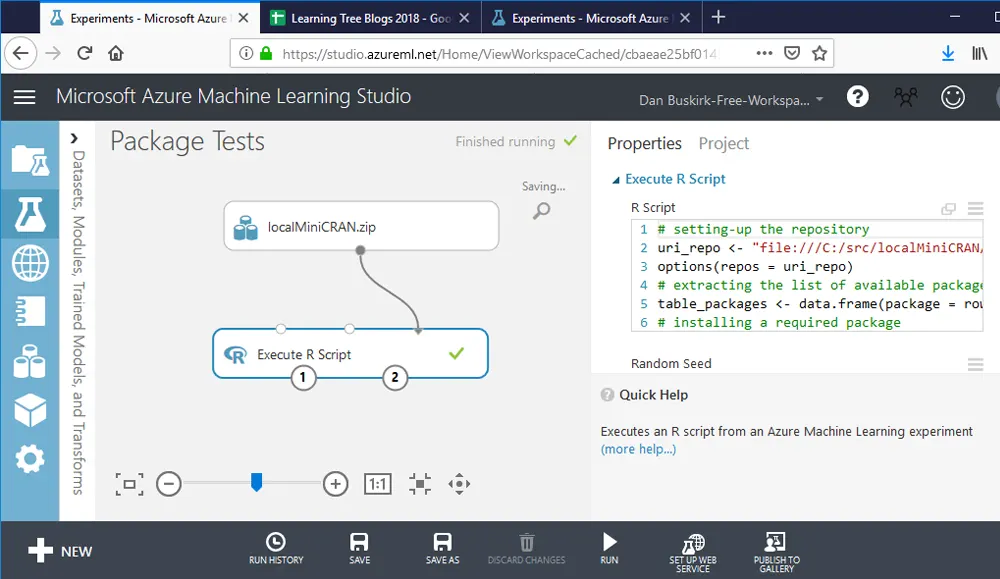
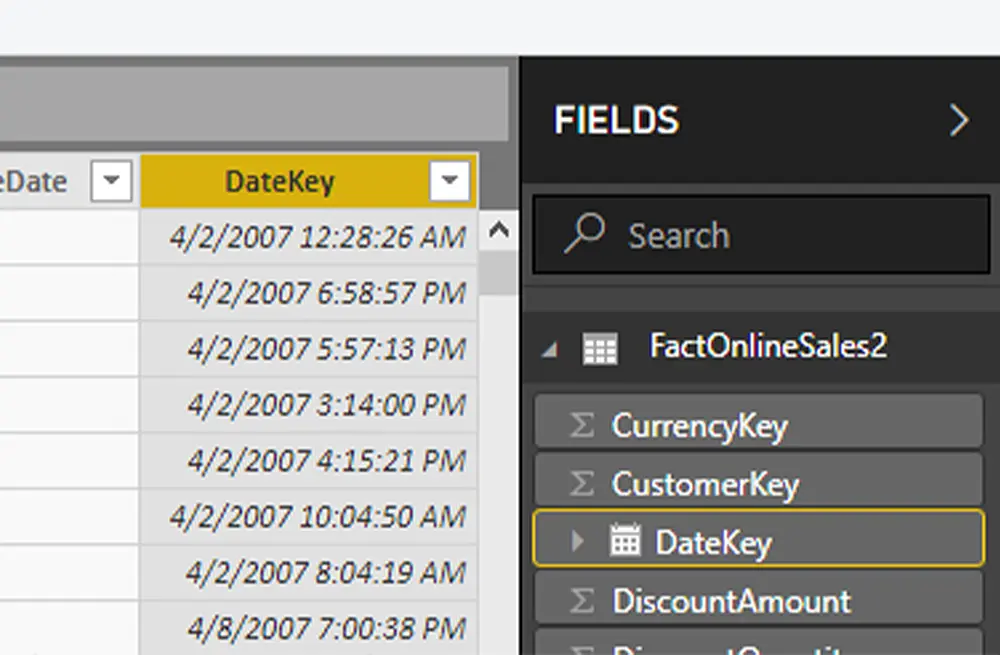
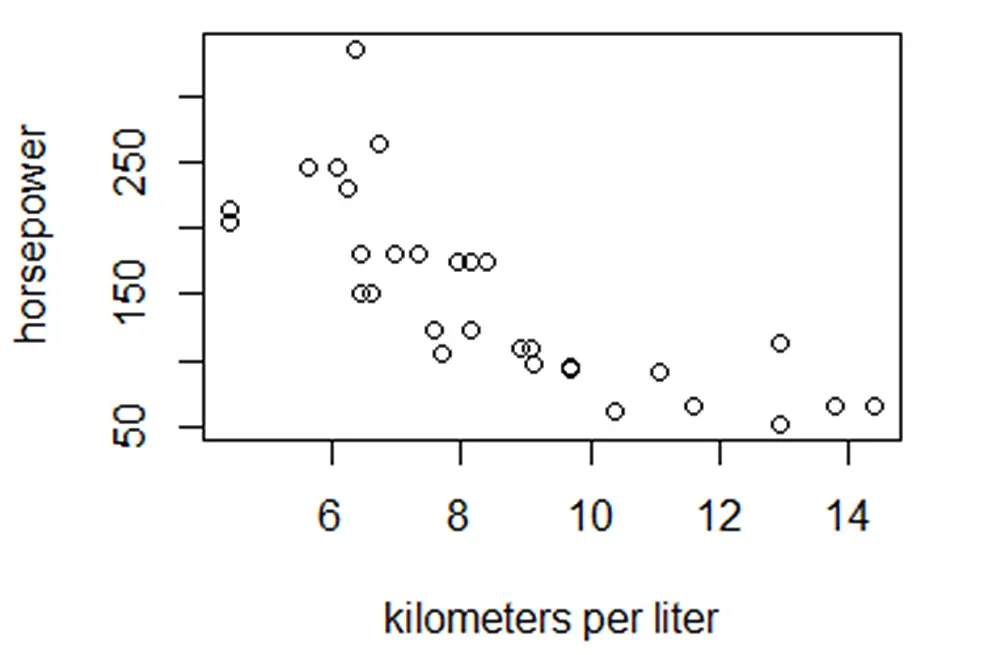
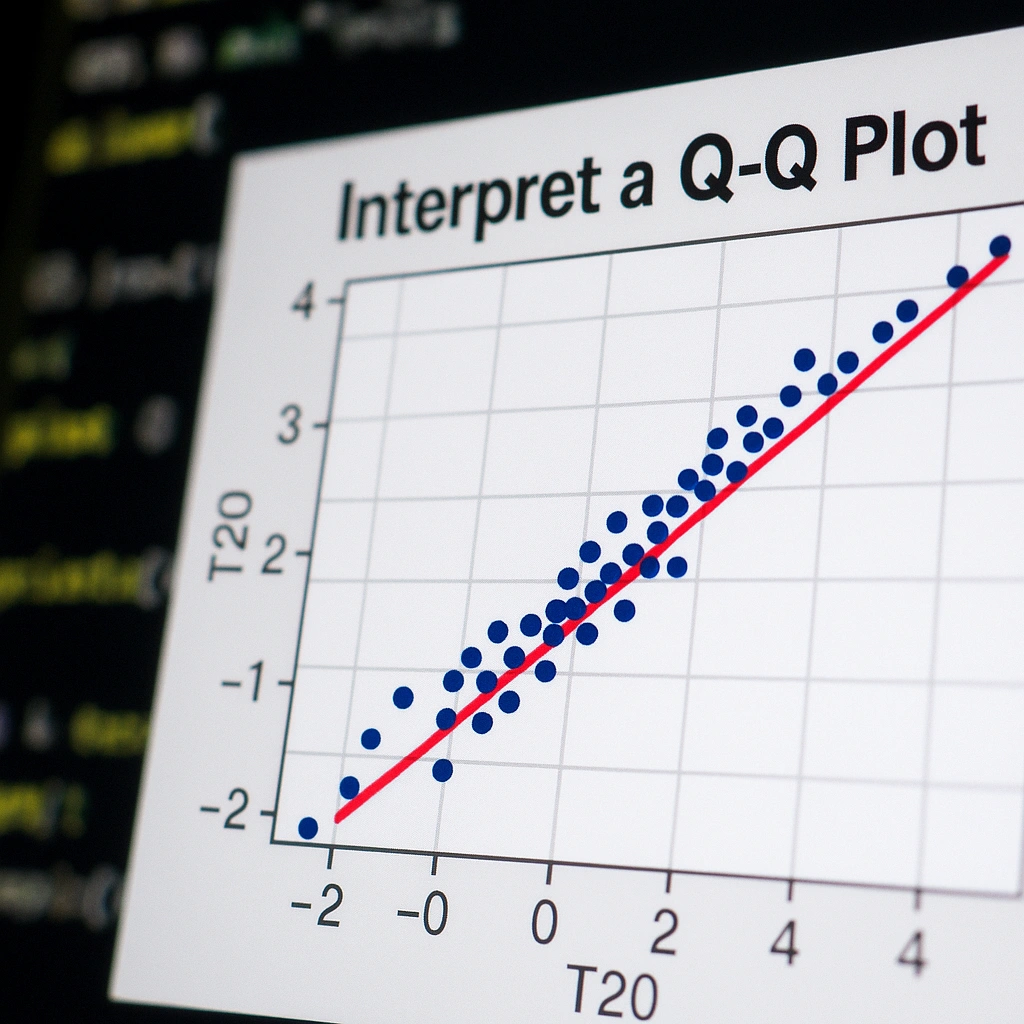
Big Data & Data Science R ProgrammingDan Buskirk
How to Interpret a Q-Q Plot
-
CybersecurityLearning Tree International
Why IT Auditors and Security Managers Should Work Together with CISA and CISM Knowledge
-
Artificial Intelligence CybersecurityLearning Tree International
Overcoming the Fear of AI: How to Get Started Without Feeling Overwhelmed
-
Advanced Leadership Certificate Program Duke CELearning Tree International
The Art of Influencing Collaborative Solutions
-
Agile ITSM Project ManagementLearning Tree International
Why Resistance to Change Is Normal and How to Overcome It
-
Artificial IntelligenceLearning Tree International
Solving AI Challenges: Work Smarter, Not Harder
-
CISA CISM Cybersecurity ISACALearning Tree International
How CISA and CISM Certifications Address Emerging Technologies like AI and Blockchain
-
Advanced Leadership Certificate Program Duke CELearning Tree International
Navigate Complexity - How to Lead With Clarity in Times of Uncertainty
-
CMMC Cybersecurity GovernmentLearning Tree International
Paving the Path to CMMC 2.0 Compliance: Key Roles
-
ITIL ITSM Service DeskLearning Tree International
Understanding ITIL Certification: Benefits, Framework, and How to Get Started
-
CISA CISM Cybersecurity ISACALearning Tree International
A Day in the Life of a CISA vs. CISM Professional
-
Advanced Leadership Certificate Program Duke CELearning Tree International
Transforming Leadership Series - Turn Your Strategy Into Action
-
Advanced Leadership Certificate Program Duke CELearning Tree International
Transforming Leadership Series - Learning Tree's Guide to Thriving in a Complex World
-
Artificial Intelligence Project ManagementLearning Tree International
AI and the Future of Project Management: How Automation is Changing the Game
-
Certification Lean Six Sigma Project ManagementLearning Tree International
Mastering Process Excellence: What is Lean Six Sigma Certification?
-
Case Study Government Power BILearning Tree International
Case Study: Judicial Council of California Empowers Courts with Tailored Power BI Training from Learning Tree
-
Case Study Certificate Programs LeadershipLearning Tree International
Case Study: Transforming Leadership Development for a Mission-Driven Government Agency
-
Process & Methodology Scaled Agile FrameworkLearning Tree International
Navigating Scaled Agile in 2025: Insights From the SAFe Summit and Beyond
-
AI Artificial Intelligence Big Data & Data ScienceLearning Tree International
The Leading 10 AI Courses to Build Your Career in 2025
-
CybersecurityLearning Tree International
Can Cyber Security Training for Employees Lower Premiums?
-
Cyber SecurityAndrew Tait
Why Rust is the Secret Weapon for Cyber Defence
-
CMMC Cybersecurity GovernmentLearning Tree International
Mastering CMMC 2.0 Compliance Timelines
-
CybersecurityLearning Tree International
Top 5 Data Security Measures Every Financial Institution Must Implement
-
CybersecurityLearning Tree International
How Banks Can Be Hacked and What You Need to Know
-
Artificial Intelligence Project ManagementLearning Tree International
The Future of Project Management: Will AI Replace the Project Manager?
-
CybersecurityLearning Tree International
Navigating the Future of Cybersecurity
-
ITIL ITSM Service DeskLearning Tree International
Applying ITIL Foundation Processes to Everyday Service Desk Operations
-
Communication Leadership Virtual TeamsLearning Tree International
Meaningful Collaboration in Virtual Teams: A Guide
-
DukeCE Leadership VUCALearning Tree International
A New Framework for Leading Org Change: Strategies for Leaders to Overcome Opposition
-
CybersecurityLearning Tree International
Why Cybersecurity Awareness Should Be Your Top Priority
-
Cybersecurity ITIL ITSMLearning Tree International
Understanding the CrowdStrike Outage: What Happened and How to Prevent Similar Incidents
-
CybersecurityLearning Tree International
The Questions You Ask When You Think You've Been Phished (and What You Should Do)
-
CybersecurityLearning Tree International
Building a Cyber-Savvy Workforce: The Key to Organizational Security
-
Agile Project Management WaterfallDr. John Hogan
The Triple Constraints of Project Management: Who Needs Them?
-
Leadership Development People Skills Project LeadershipJonathan Gilbert
Leadership Development for Individual Contributors: Why it's Essential
-
CybersecurityJohn McDermott
Examples of Defense in Depth: The Stealth Cybersecurity Essential
-
Business Applications Microsoft Microsoft Certifications Microsoft OfficeNancy Tandy
Find the Right Microsoft Power Platform Certification for You
-
Duke CE Leadership StrategyJonathan Gilbert
The Architect-Translator-Doer Model: Your Key to Success
-
Business Cybersecurity StrategyJohn McDermott
Why Least Privilege Access is Critical to Cybersecurity
-
AI Business Machine LearningAlastair Brown
4 Essential Business AI Solutions to Begin Your AI Journey
-
CompTIA Cyber SecurityChristian Owens
Your Guide to CompTIA Security+ SY0-701
-
PRINCE2 Project ManagementBen Beaury
From Principles to People: Your guide to PRINCE2® 7 [2024]
-
Cyber SecurityAaron Kraus
How to Combat Imposter Syndrome in the Cyber Security Career Field
-
Artificial Intelligence Big Data & Data SciencePackt
How can Artificial Intelligence support your Big Data architecture?
-
CMMC Cyber SecurityDaniel Turissini
Building Blocks for Cyber Security Maturity and Opportunities to help protect the USA Supply Chain
-
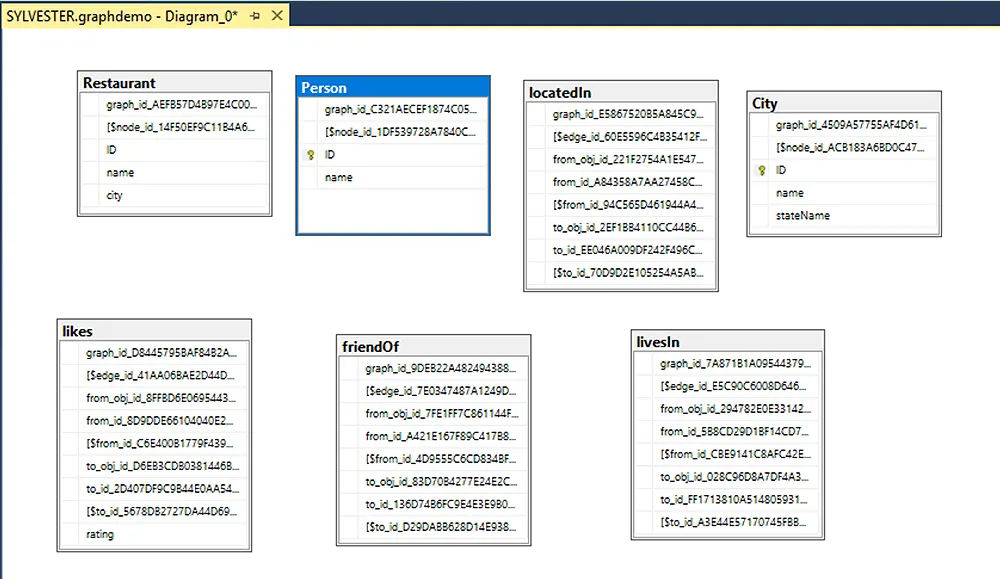
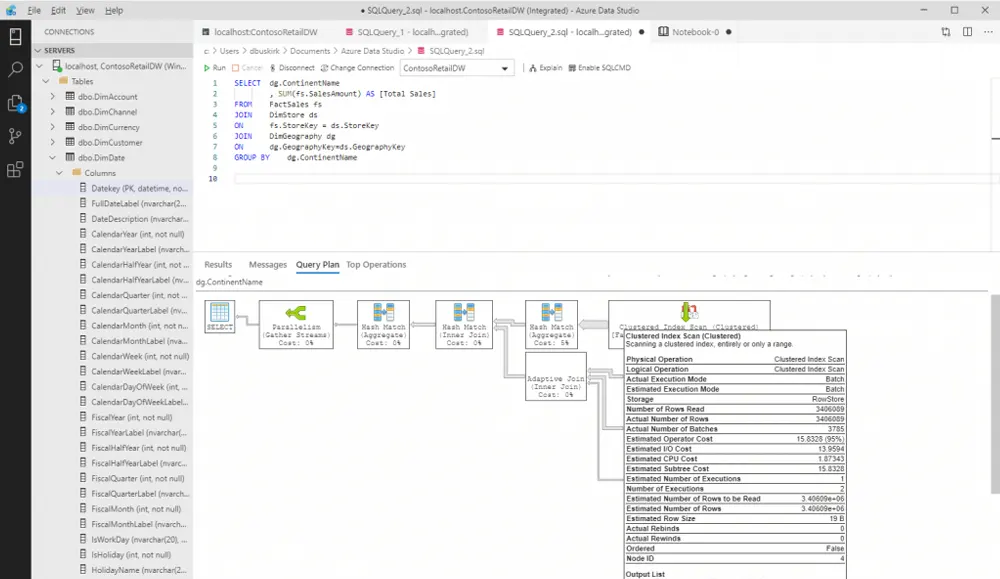
Business Analysis SQL ServerDan Buskirk
SQL Server's Graph Database for Contacts and Connections
-
R Programming SQL ServerDan Buskirk
SQL Server! Now with Built-In AI!
-
SQL SQL ServerDan Buskirk
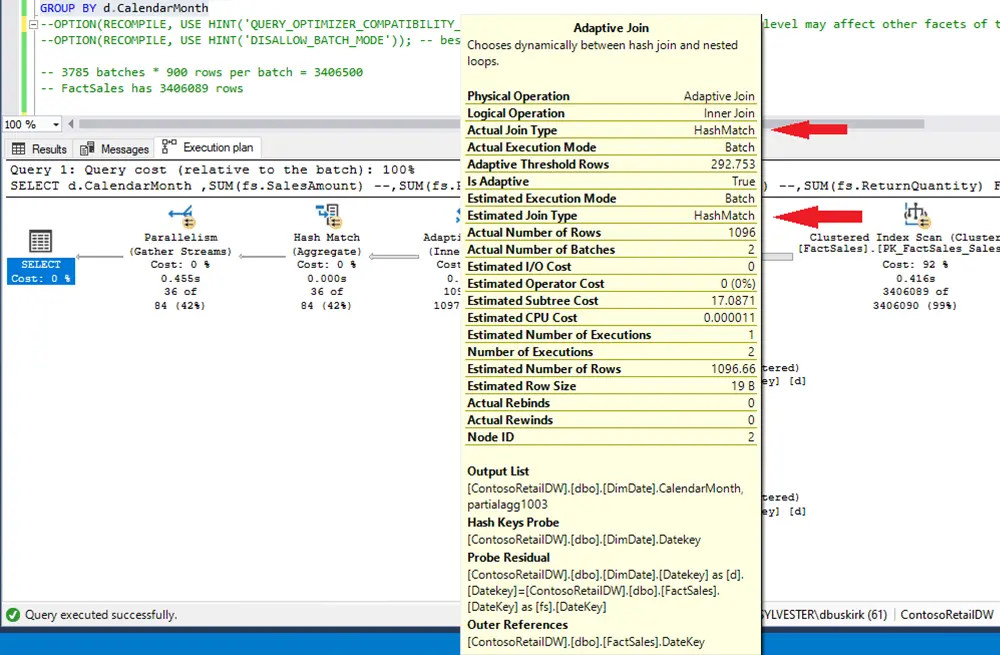
Some Query Hints: Undocumented, But Interesting
-
Azure IoTDan Buskirk
Setting Up VS Code to Program Azure IoT Devices
-
Microsoft Office Training and DevelopmentArnold Villeneuve
Perform a Mail Merge with Word and Excel
-
Cloud Computing Microsoft Office Workforce Optimization SolutionsJohn McDermott
Make Google Docs (G Suite) More Powerful with Extensions
-
SQL ServerDan Buskirk
SET NOCOUNT ON Is More Important Than You Think
-
Cyber Security QuizLearning Tree International
QUIZ: Does your Organization Cultivate an Enterprise-Wide Culture of Cyber Security Responsibility?
-
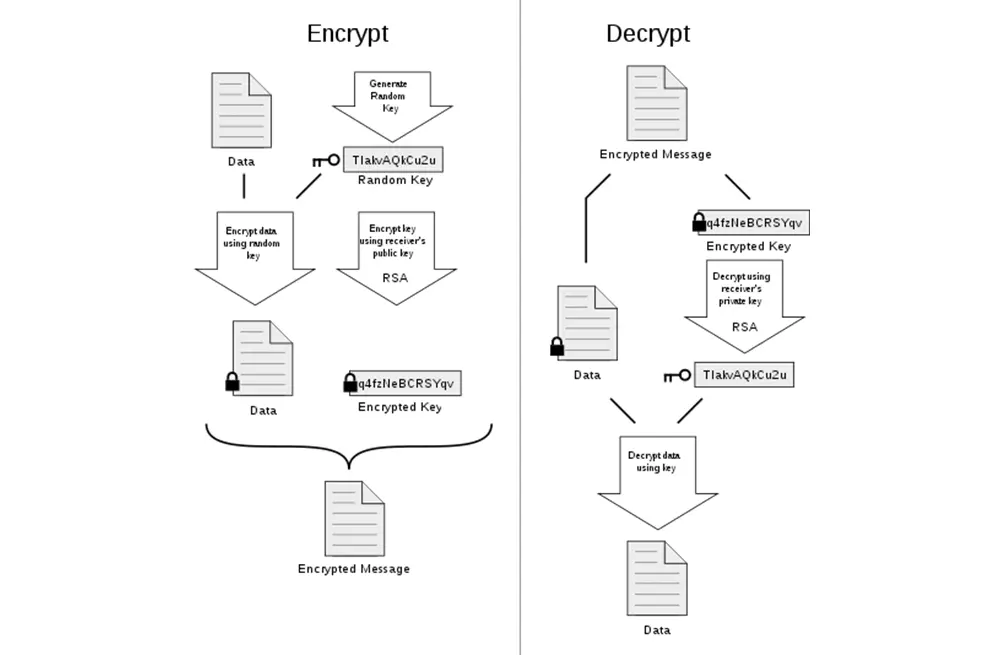
CISSP Cloud Cyber SecurityAaron Kraus
Protect Secrets in the Cloud with Homomorphic Encryption
-
Cyber SecurityJohn McDermott
Cyber Security Is Not Just For Computer Nerds
-
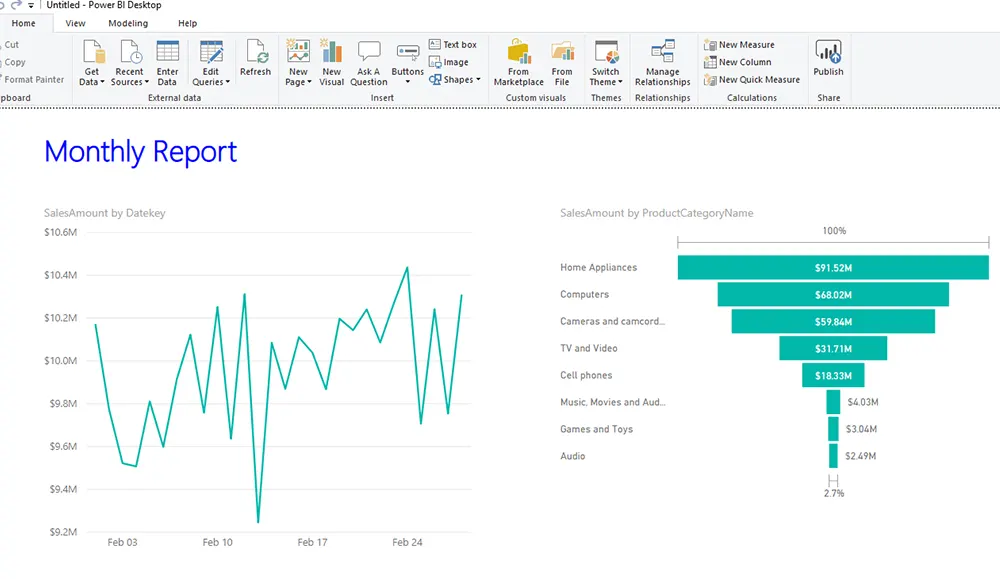
Business Intelligence Microsoft OfficeDan Buskirk
Power BI: Creating and Sharing Power BI Templates
-
DSC PowerShellMike Covington
PowerShell Desired State Configuration
-
Cyber Security Linux and UNIXBob Cromwell
Practical Steps Toward Compliance With OpenSCAP
-
Python Web DevelopmentDan Buskirk
Parallel or Perish: Distributed Multiprocessing with MPI and Python
-
Cyber SecurityJohn McDermott
NIST Wants Comments on Secure Software Development
-
Cyber SecurityAaron Kraus
NICE Framework: "Oversee and Govern" Challenges
-
Cyber SecurityAaron Kraus
NICE Framework: "Operate and Maintain" Challenges
-
Business Analysis CommunicationPeter Vogel
Must Have Business Analysis Tools and Techniques
-
Microsoft OfficeArnold Villeneuve
Microsoft Word Add-Ins for Productivity
-
Business Analysis Business Intelligence Microsoft OfficeArnold Villeneuve
Microsoft Excel Add-Ins Make You More Productive
-
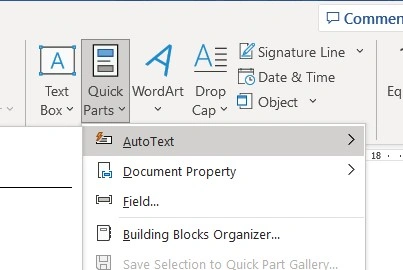
Microsoft OfficeArnold Villeneuve
Work fast with Microsoft Word Quick Parts
-
Project ManagementDavid Hinde
What Makes a Project Successful?
-
Artificial Intelligence Azure Cloud Computing MicrosoftSandra Marin
Master the Basics of Microsoft Azure—Cloud, Data, and AI
-
Certification Cloud Cloud ComputingLearning Tree International
Empowering Your Cloud Journey: The Benefits of Earning Cloud Certifications
-
Microsoft OfficeArnold Villeneuve
Listen to your Outlook email messages and Word documents with Read Aloud!
-
Cybersecurity Cyber SecurityAaron Kraus
12 Cybersecurity Tips to Stay Cyber Aware All Year Long
-
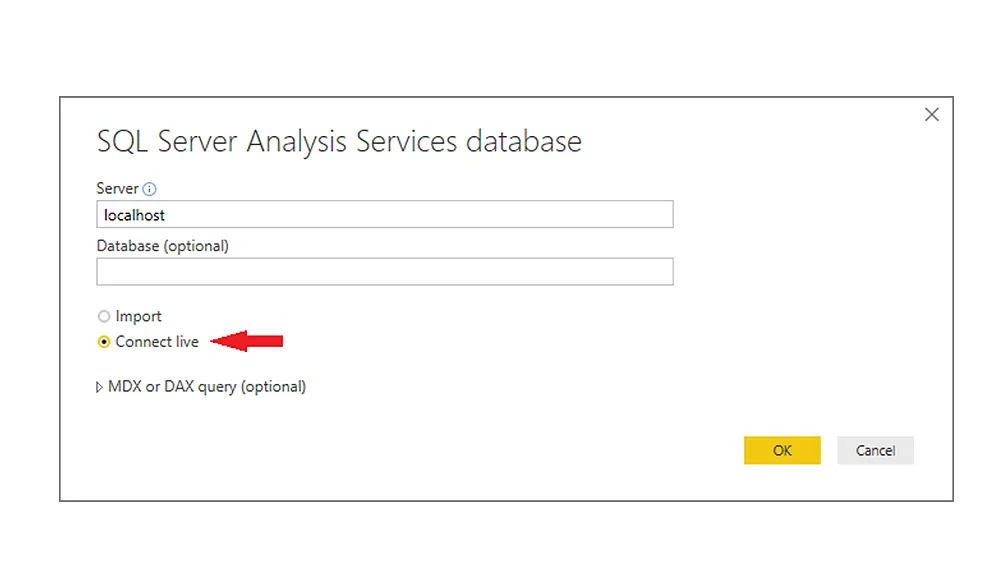
Business Intelligence SQL ServerDan Buskirk
Live SQL Server Data in Power BI: Using DirectQuery
-
Business Applications Microsoft Microsoft Certifications Microsoft OfficeLearning Tree International
The Power in the Microsoft Power Platform
-
COBIT® & TOGAF® ITIL(r)Alison Beadle
Let's Explore ITIL® 4
-
Microsoft Office SharePointMalka Pesach
Introduction to PowerApps: What is PowerApps and How to Get Started
-
Business Intelligence Microsoft OfficeDan Buskirk
Introduction to M, the Power Query Formula Language
-
Big Data & Data Science Business Analysis Business Intelligence R Programming SQL ServerDan Buskirk
MS Machine Language Server for Enterprise-Grade Analytics
-
Business Analysis Business Intelligence Microsoft OfficeDan Buskirk
Interactive Visio Diagrams in Power BI Reports
-
AI Cyber Security Machine LearningJohn McDermott
Unlocking the Power of AI to Bolster Cybersecurity Defenses
-
AzureAaron Kraus
Five Benefits of Azure Data Factory
-
Big Data & Data Science Business IntelligenceDan Buskirk
Does Intel Python Deliver?
-
Cyber SecurityJohn McDermott
InfoSec and Cybersecurity Concerns for a Mobile-First Distributed Workforce
-
Cyber SecurityJohn McDermott
How Are Fiber Optic Cables Used For (Physical) Intrusion Detection?
-
Microsoft Office SharePointMalka Pesach
External Sharing is EASY with SharePoint Online
-
Web DevelopmentJohn McDermott
Encoding a Web Page In the URL
-
Project ManagementRobert Annis
Where does Agile fit into Project Management and vice versa?
-
Agile & Scrum Communication Leadership Project Management Workforce Optimization SolutionsAlan O'Callaghan
What Is A Team?
-
Project ManagementRobert Annis
The 7 Essential Project Management Skills
-
Agile & Scrum Project ManagementRobert Annis
What is The Agile Project Manager?
-
Agile & ScrumAlan O'Callaghan
Do You Speak Agile?
-
SQL ServerDan Buskirk
SQL Server: Users Without Logins?
-
Cyber Security .NET/Visual StudioJasper Kent
.NET Core In-Memory Database
-
Web DevelopmentJohn McDermott
The "data" URL
-
Big Data & Data Science R ProgrammingDan Buskirk
Effective use of RevoScaleR Transformations
-
Certification Microsoft Technical SkillsDebbie Uttecht (She/Her)
Skill up with Microsoft Learning Partners
-
CybersecurityJohn McDermott
Eavesdropping On Computers From Afar
-
Networking & VirtualizationJohn McDermott
What Is The Difference Between Single-mode and Multi-mode Fiber?
-
Cyber Security Networking & VirtualizationJohn McDermott
Is IPv6 Less Secure Without NAT?
-
Networking & VirtualizationJohn McDermott
How do tshark, ngrep, and tcpdump Differ and When to Use Them
-
Linux and UNIX Networking & VirtualizationIan Darwin
Dovecot is Now My Favorite Unix/Linux IMAP Mail Download Server
-
Agile & Scrum Project ManagementLearning Tree International
Disciplined Agile: Is It Right for Me?
-
Microsoft OfficeArnold Villeneuve
How to easily create a newsletter template in Microsoft Word
-
DevOpsMarc Hornbeek
DevSecOps Practices Gap Assessment
-
Cyber SecurityJohn McDermott
DDoS for Hire: FBI Shuts Down Amplifiers
-
Project ManagementDavid Hinde
Mastering Gantt Charts vs Burndown Charts: A Battle of the Planning Tools
-
Communication Training and DevelopmentNicole Fiorucci
Customer Service Chat Support: Top Survival Tactics
-
Big Data & Data Science Business Intelligence .NET/Visual StudioDan Buskirk
Curing Python Envy with ML.Net
-
Business Analysis R Programming SQL ServerDan Buskirk
Cube Data and MDX Queries in R
-
LeadershipLisa Bazlamit
4 Things Every Woman Leader Should Do Right Now — Transformational Leadership for Women
-
Cyber SecurityJackie Visnius
CISSP Certification Exam Changes: What You Need to Know
-
.NET/Visual StudioDan Buskirk
C# Nullable References
-
Business AnalysisPeter Vogel
Crafting a Strategic Response to the World You Live in with PESTLE
-
Big Data & Data SciencePackt
What is the Carbon Footprint of AI and Deep Learning?
-
Cyber SecurityBob Cromwell
How to Choose a Cybersecurity Certification
-
homepage SQL ServerDan Buskirk
Batch Mode Processing in SQL Server 2019
-
SQL ServerDan Buskirk
Azure Data Studio: SQL Server Tools for Linux, Mac, Oh, and Windows Too
-
Cyber Security homepageJohn McDermott
Authenticating Your Email Domain With DKIM
-
SQL ServerDan Buskirk
Artificial vs Surrogate Keys: A Star-Crossed Database Debate
-
PowerShellMike Covington
One-Touch Menus in PowerShell Console
-
Cybersecurity Social EngineeringJohn McDermott
Cyber Essentials: Five Current Cyber Security Threats to Watch Out For
-
Cybersecurity Social EngineeringJohn McDermott
Cyber Essentials: Phishing and Other Social Engineering Impersonations
-
Cyber SecurityJohn McDermott
Cyber Essentials: Time to Pass on Your Passwords
-
Big Data & Data Science Project ManagementLearning Tree International
Data-Driven Project Management: Must-Know Best Practices
-
Artificial Intelligence Azure Big Data & Data Science Microsoft CertificationsLearning Tree International
Microsoft's New Role-Based Azure Certifications - What You Need to Know
-
Cloud Computing Cyber SecurityBob Cromwell
The CCSP Cloud Security Certification is Hot, How Can I Prepare?
-
ITIL(r)Hitesh Patel
Handling Permacrisis: The Shift of the ITIL® Ecosystem
-
Agile & Scrum SAFeJoseph Danzer
Learning Tree Instructor Spotlight: Eshan Chawla
-
Cyber SecurityLearning Tree International
Social Engineering Basics - Is Your Business At Risk?
-
Cybersecurity Remote WorkingJohn McDermott
A Primer on Cybersecurity For Students and Families Schooling at Home
-
Cybersecurity Process Improvement SecDevOpsGreg Adams
SecDevOps: Increasing Cybersecurity Threats Means Security Must Come First
-
Duke CE LeadershipJonathan Gilbert
The Game Has Changed for Businesses and for Leaders
-
Duke CE LeadershipJonathan Gilbert and Michael Canning
What is Transformational Technical Leadership and Why Does It Matter in 2022?
-
Business ApplicationsMartyn Baker
Manage Yourself and Manage Your Team with Office 365
-
R ProgrammingDan Buskirk
GPU Processing in R: Is it worth it?
-
homepage Workforce Optimization SolutionsJohn McDermott
How to Use PortableApps to Make Your Life Easier
-
Workforce Optimization SolutionsJohn McDermott
Stick Your Documents On An e-Reader
-
Cyber SecurityJohn McDermott
The New CWE List is Out: There Are A Lot of Familiar Entries
-
SQL ServerDan Buskirk
SQL Server 2019: Can Dr. Froid Help Your User Defined Functions?
-
Big Data & Data Science Cloud Computing Linux and UNIX .NET/Visual StudioJohn McDermott
How deMorgan's Theorems Can Help Programmers
-
Big Data & Data ScienceDan Buskirk
Tensorflow 2.0 and Keras
-
Big Data & Data Science Business Intelligence Microsoft OfficeDan Buskirk
Organize Your DAX Measures in Power BI
-
Business Applications Microsoft OfficeDan Buskirk
Pasting Datetime Data into Excel Workbooks
-
Big Data & Data Science PythonDan Buskirk
Using a Pandas Andrews Curve Plot for Multidimensional Data
-
Cyber SecurityJohn McDermott
What Is A Digital Signature?
-
Cyber SecurityJohn McDermott
Beware The Social Engineer
-
Artificial Intelligence Machine LearningDan Buskirk
Text analytics: Words, Numbers, and Vectors
-
Big Data & Data ScienceImran Ahmad
Implementing Deep Learning Concepts Through Neural Networks
-
CMMCBrett Osborne
2021 CMMC AB Town Hall: A Recap
-
CMMC Cyber SecurityBrett Osborne
The CMMC Roles: CCP (Certified CMMC Professional)
-
CMMC Cyber SecurityBrett Osborne
The CMMC Roles: RP (Registered Practitioners)
-
CMMC Cyber SecurityBrett Osborne
CMMC: Not Just Your 800-171 Anymore!
-
DevOpsMarc Hornbeek
Harnessing the Power of Software Value Streams
-
Cyber SecurityJohn McDermott
Update Your Server's TLS
-
Leadership Training and DevelopmentJohn McDermott
Learning Through Projects
-
Cyber SecurityJohn McDermott
Real-life Public Key Encryption (And Why It Matters)
-
Big Data & Data ScienceAndrew Tait
The 2 Data Science Topics Every CEO Should Care About
-
Big Data & Data ScienceLearning Tree International
Which Job Roles Make Up the Data Science Dream Team?
-
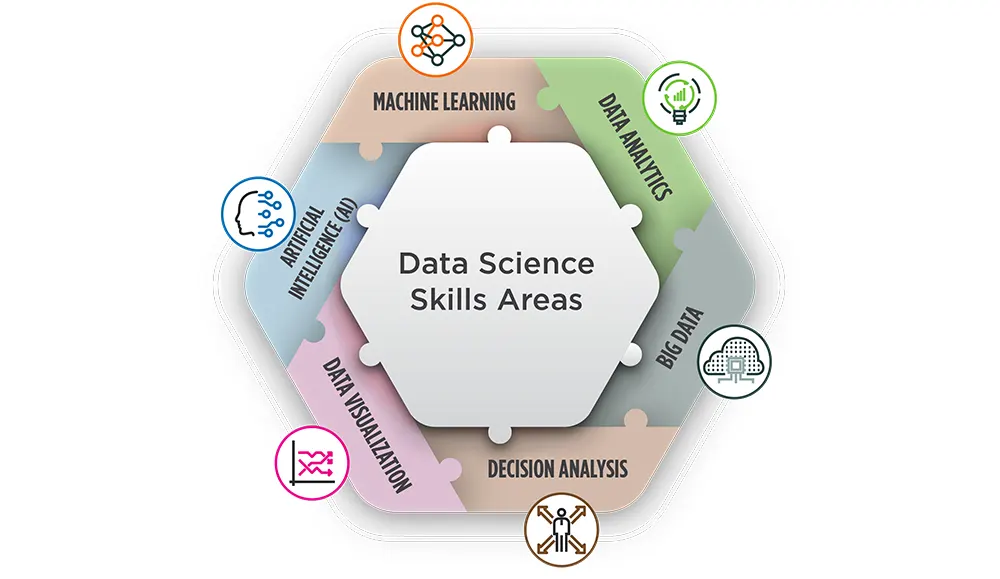
Big Data & Data ScienceLearning Tree International
The 6 Major Skill Areas of Data Science
-
Cyber SecurityJohn McDermott
Security Should be Simple For the End-User?
-
Networking & VirtualizationJohn McDermott
Three Measures of Availability in Cybersecurity
-
Cyber SecurityJohn McDermott
Password Cracking Just Got Easier
-
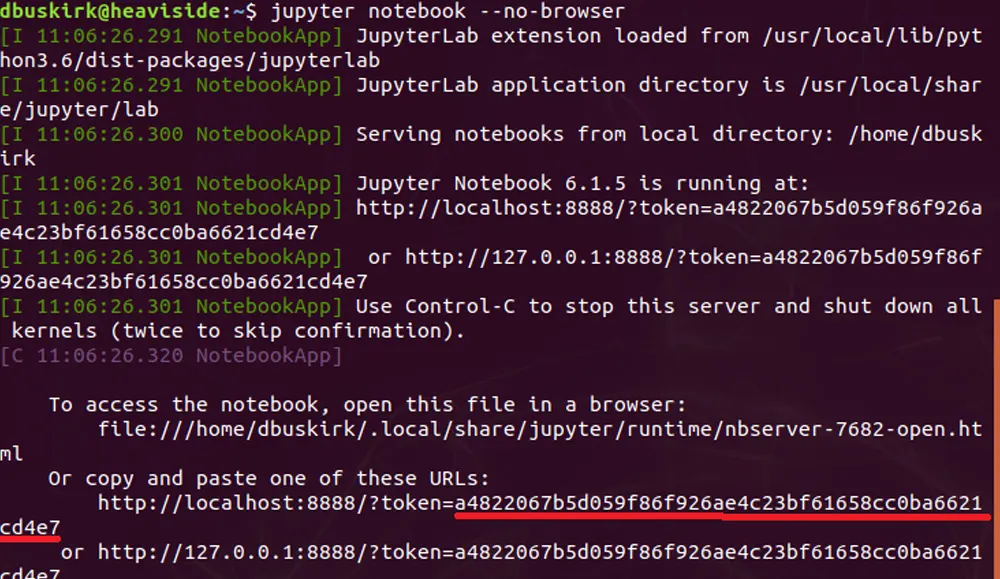
Artificial Intelligence .NET/Visual Studio PythonDan Buskirk
Using a Desktop Browser to Connect to Jupyter on Jetson Nano Edge Device
-
Cyber SecurityJohn McDermott
People May be Too Fearful of Phishing Now
-
Cyber SecurityJohn McDermott
Update Your Browser Now
-
Cyber SecurityJohn McDermott
Is Anonymous Data Really Anonymous?
-
Training and DevelopmentJohn McDermott
The Benefits of Spaced Repetition
-
Adaptive Learning Communication Project Management Training and DevelopmentJohn McDermott
Failure in Learning Part II: The Importance of the Debrief and Coaching
-
Communication Project Management Training and DevelopmentRobert Annis
Organisational Psychology: Our Values
-
Artificial Intelligence Big Data & Data Science Business Intelligence Python R ProgrammingDan Buskirk
Parallel or Perish - An Overview
-
Project ManagementLearning Tree International
The New PMP Certification -- What You Need to Know!
-
Cyber Security DevOpsJohn McDermott
DevSecOps Requires Integrating Cyber Security From the Start
-
Cyber SecurityAaron Kraus
Introduction to the NICE Framework
-
Cyber SecurityAaron Kraus
NICE Framework: "Securely Provision" Challenges
-
Cyber SecurityAaron Kraus
NICE Framework: "Protect and Defend" and "Analyze" Challenges
-
Cyber SecurityAaron Kraus
NICE Framework: "Collect and Operate" and "Investigate" Challenges
-
Cyber SecurityJohn McDermott
More Unsecured Unencrypted Cloud Data Exposed
-
Adaptive Learning Training and DevelopmentJohn McDermott
Social, Team, and Pair Learning
-
Training and DevelopmentJohn McDermott
We Learn A Lot From Our Mistakes
-
Cyber SecurityJohn McDermott
More Bad Password Advice and More Good Password Advice
-
Cyber SecurityJohn McDermott
Voice Assistants at Work: Can You Trust Them Not To Eavesdrop?
-
Cyber Security Networking & VirtualizationJohn McDermott
Mozilla To End ftp Support. What Are the Alternatives?
-
Cyber SecurityJohn McDermott
New Concerns About Uses of Facial Recognition
-
Business Applications Microsoft Microsoft OfficeLearning Tree International
Microsoft Teams and SharePoint: Working Together
-
Agile & ScrumLearning Tree International
Top 10 Agile Lessons Learned from an Actual Practicing Scrum Master and Product Owner
-
Training and DevelopmentJohn McDermott
Do You See Classroom Training in the Future?
-
Remote Working Training and DevelopmentRobert Annis
Technology of the Remote Worker
-
Azure PythonDan Buskirk
Using Postman to Learn the Azure Artificial Intelligence APIs
-
Cyber SecurityJohn McDermott
Browsers Will Soon No Longer Accept Older Certificates
-
Remote Working Training and DevelopmentRobert Annis
Organizational Policy Changes and Shifts
-
Leadership Project Management Training and DevelopmentRobert Annis
Leadership in Remote Working Organizations
-
Cyber SecurityJohn McDermott
Company Computers At Home as Reverse BYOD
-
Remote Working Training and DevelopmentRobert Annis
A Day in the Life of a Post-Pandemic Worker
-
Cyber SecurityJohn McDermott
Is Your Printer Endangering Your Network?
-
Cyber SecurityJohn McDermott
There Is Another Flaw In Computer Processor Chips
-
Remote Working Training and DevelopmentRobert Annis
Impact of the Pandemic
-
Cyber SecurityJohn McDermott
What is an "Evil Maid" Attack and Why Should You Care?
-
Remote Working Training and DevelopmentRobert Annis
Remote Work is the Future -- but What will that Future Look Like?
-
Cyber SecurityJohn McDermott
Replacing Google Authenticator
-
Microsoft OfficeJohn McDermott
Understanding Office 365 Groups
-
Remote Working Training and DevelopmentRobert Annis
First Tips For Moving To Online Learning
-
Communication Training and DevelopmentJohn McDermott
Selecting and Taking Online Training, Especially for Cyber Security Topics
-
Business Analysis Cyber SecurityJohn McDermott
Using Cyber Security Frameworks to Identify Training Needs
-
LeadershipMalka Pesach
Women's History Month: Interview with Malka Pesach
-
Remote Working Training and DevelopmentLearning Tree International
6 Virtual Instructor-Led Training Myths Busted with AnyWare
-
Remote WorkingLearning Tree International
Remote Managers: 5 Tips to Stay Connected to Your Team
-
LeadershipLearning Tree International
Women's History Month: Interview with Ajitha Srinivasan
-
Big Data & Data ScienceJohn McDermott
Data Presentation Tips
-
SQL ServerDan Buskirk
Keras: One API to Rule them All
-
Cyber SecurityJohn McDermott
Deepfakes: Beauty and Ugliness
-
COBIT(r) & TOGAF(r) ITIL(r)Alison Beadle
Let's Explore ITIL 4 Certification Beyond Foundation
-
COBIT(r) & TOGAF(r) ITIL(r)Alison Beadle
How to transition from ITILv3 to 4
-
Cyber SecurityJohn McDermott
Happy Safer Internet Day
-
COBIT(r) & TOGAF(r) ITILAlison Beadle
Let's Explore the ITIL 4 Foundation Certification
-
Adaptive Learning Blended Training COBIT(r) & TOGAF(r) ITIL(r) Training and DevelopmentRonald Stanley
Classroom and Online Training Are Broken... But They Fix Each Other
-
Cyber SecurityJohn McDermott
How to Protect Yourself From SIM Swapping Attacks
-
AzureLearning Tree International
Discovering Microsoft Azure Apps & Infrastructure Training Paths
-
Adaptive Learning COBIT(r) & TOGAF(r) ITIL(r)Alison Beadle
ITSM & Digital Transformation: The Future is Built on ITIL®
-
Linux and UNIXJohn McDermott
UNIX: Fifty Years and Counting
-
.NET/Visual Studio Web DevelopmentPeter Vogel
Blazor: Why, When...and Your Future
-
COBIT(r) & TOGAF(r) ITIL(r)Alison Beadle
Reasons the Future is Built on ITIL 4
-
Cyber SecurityJohn McDermott
The Perils of Re-Using Passwords
-
Web DevelopmentIan Darwin
Developers: Get Good with your IDE for Productivity
-
Project ManagementDavid Hinde
Why Do So Many Projects Deliver Late? (And How to Avoid this on our Projects)
-
Training and DevelopmentJohn McDermott
Know Why You Want To Learn
-
Big Data & Data Science Business Intelligence PythonDan Buskirk
Beware the Local Minima
-
Project ManagementJohn McDermott
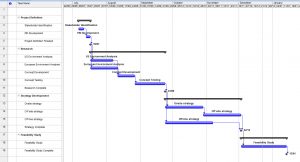
Introduction to Gantt Charts: A Tool For Everyone Part Two
-
Microsoft Office Mobile App Development SharePointMalka Pesach
PowerApps: Save Your Data Offline
-
Project ManagementJohn McDermott
Introduction to Gantt Charts: A Tool For Everyone Part One
-
Adaptive Learning Training and DevelopmentJoseph Danzer
A Personal Use Case about Why Adaptive Learning Is, In Fact, Cool (IMO)
-
Cyber SecurityBob Cromwell
How To Enter The Cyber Security Field
-
Cyber Security Networking & VirtualizationJohn McDermott
Your Wi-Fi Can Be Heard a Long Way Away
-
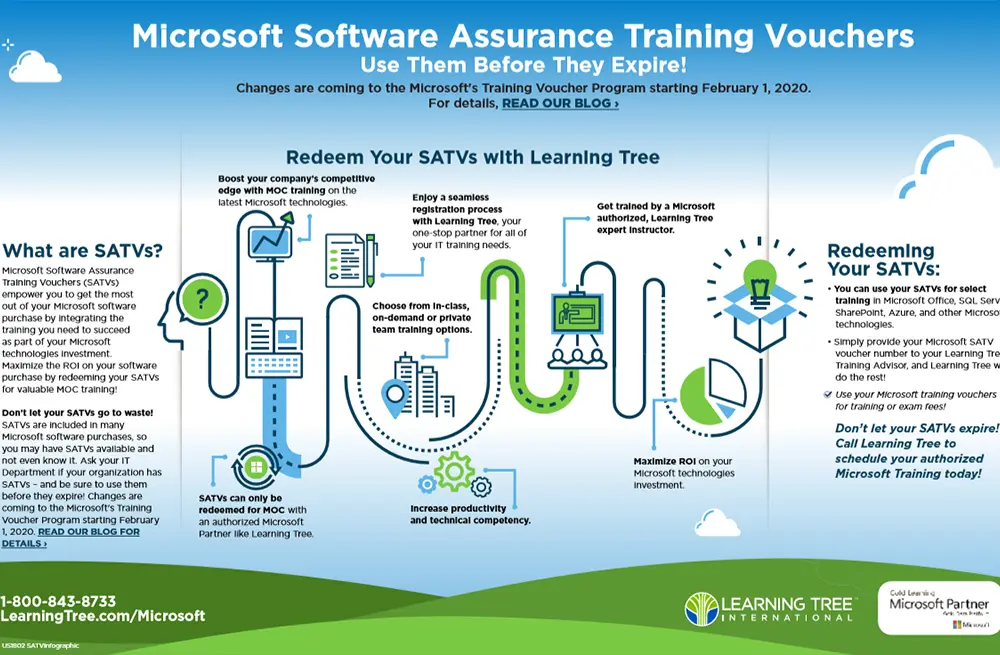
MicrosoftJoseph Danzer
Microsoft SATVs Updates -- What's Changing and What You Need to Know
-
Big Data & Data Science Cyber SecurityJackie Visnius
Data Doomsday: The Ransomware Call
-
Cyber SecurityJackie Visnius
BYOD Recharged: 3 Security Challenges to Consider
-
Cyber SecurityJohn McDermott
Social Spies: How Governments and Companies Use Social Media for Intel
-
Cyber SecurityJackie Visnius
Thinking in the Security Context
-
Cyber Security Training and DevelopmentJohn McDermott
Do or Don't: It Makes a Difference to the Cyber Security Mindset
-
Cyber SecurityJohn McDermott
Beware the (Online) Game
-
Cyber SecurityLearning Tree International
Your #CyberAware Checklist
-
.NET/Visual StudioDavid Hinde
Seven Steps to Successfully Closing a Project
-
Artificial IntelligencePackt
Do you need artificial intelligence and machine learning expertise in house?
-
Project ManagementLearning Tree International
The Fallacy of Project Management
-
Project ManagementLearning Tree International
Project Management Without Borders
-
Project ManagementDavid Hinde
Seven Steps to a Successful Project Start Up
-
COBIT® & TOGAF® ITIL(r)Learning Tree International
The Case for ITIL 4
-
COBIT(r) & TOGAF(r) ITIL(r)Learning Tree International
Transitioning to ITIL 4 - Is It Worth It?
-
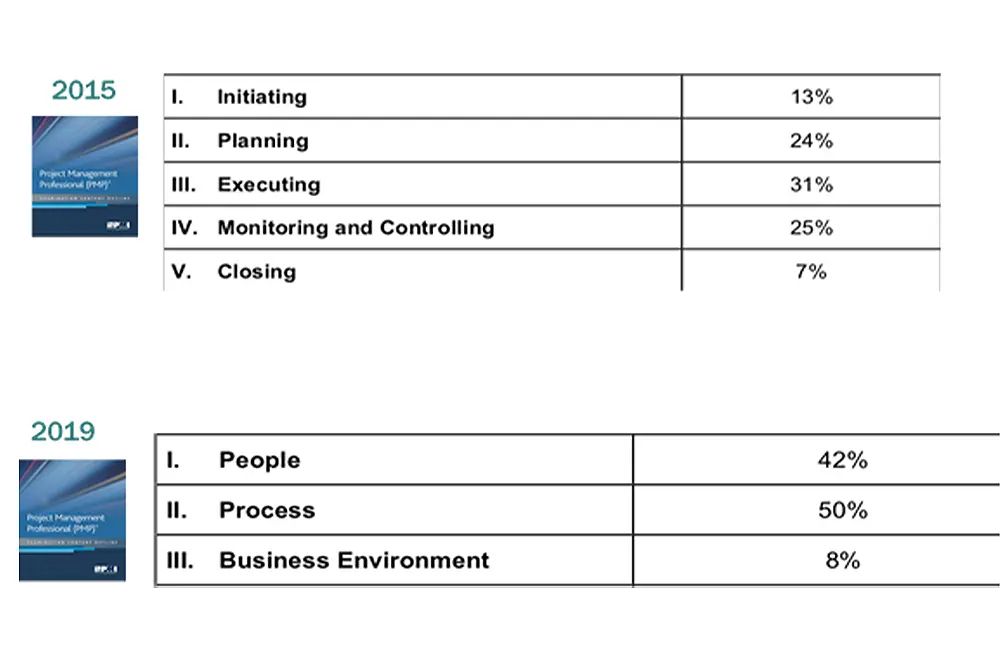
Project ManagementJoseph Danzer
Upcoming PMP Exam Changes: An Overview
-
Cyber SecurityJohn McDermott
What Is a GAN And Is It Dangerous?
-
Big Data & Data SciencePackt
Quantum computing, edge analytics, and meta learning: key trends in data science and big data in 2019
-
PythonPackt
5 best practices to perform data wrangling with Python
-
AWS Cloud Computing Cyber SecurityJohn McDermott
Facial Recognition Is Now Easy to Implement: What Does That Imply?
-
Microsoft OfficeJen McFarland
Microsoft Teams: Tips from an Early Adopter
-
Networking & VirtualizationJohn McDermott
How To Use wget To Download Websites
-
Project ManagementDavid Hinde
Seven Key Steps for Project Risk Management
-
Cyber SecurityJohn McDermott
Shut Off The Engine! Default Passwords Can Disable Your Car!
-
Training and DevelopmentLearning Tree International
Getting to Know Our AnyWare Staff: Ash Ummat
-
Cyber SecurityJohn McDermott
Another Breach of Data Stored In The Cloud. Please stop.
-
Project ManagementDavid Hinde
Seven Common Misconceptions about Agile Project Management
-
Training and DevelopmentLearning Tree International
#AnyWareIRL -- Happy 10th Anniversary, AnyWare!
-
Big Data & Data Science R ProgrammingDan Buskirk
Using Tensorflow with R
-
Cyber SecurityJohn McDermott
Physical Security is Still Important, Maybe it is More So Than Ever Before
-
Cyber Security Linux and UNIXBob Cromwell
Vulnerability Scanners: How Helpful Are They?
-
Linux and UNIX Mobile App Development .NET/Visual Studio PowerShell Web DevelopmentJohn McDermott
Why Order Matters
-
Azure Big Data & Data Science R ProgrammingDan Buskirk
Loading New R Packages into AzureML
-
Mobile App DevelopmentIan Darwin
Flutter: Your New Friend for Mobile App Development
-
Cyber SecurityJohn McDermott
The Brave Web Browser: Faster and More Secure
-
Cyber SecurityJohn McDermott
What is Credential Stuffing and Why Should I Care?
-
Agile & ScrumRobert Annis
Does Agile Transform a Business?
-
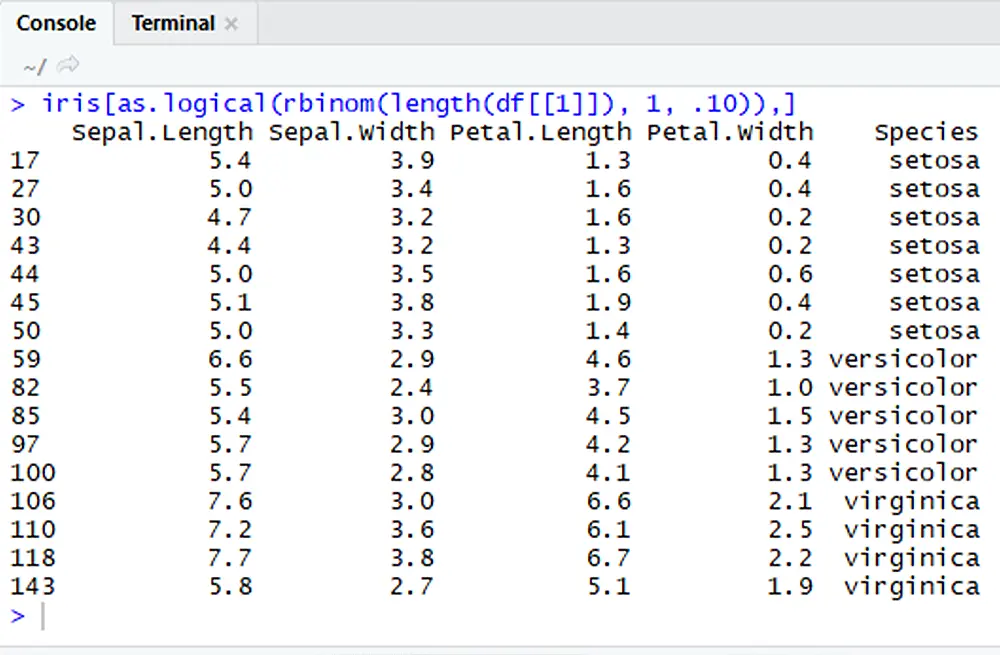
Big Data & Data Science R ProgrammingDan Buskirk
Randomly Sampling Rows in R
-
Cyber SecurityJohn McDermott
A Cyber Security Income Opportunity: Freelance Bug Finder
-
Business Intelligence SQL ServerDan Buskirk
New Improved SQL Server 2019! Now with more Spark!
-
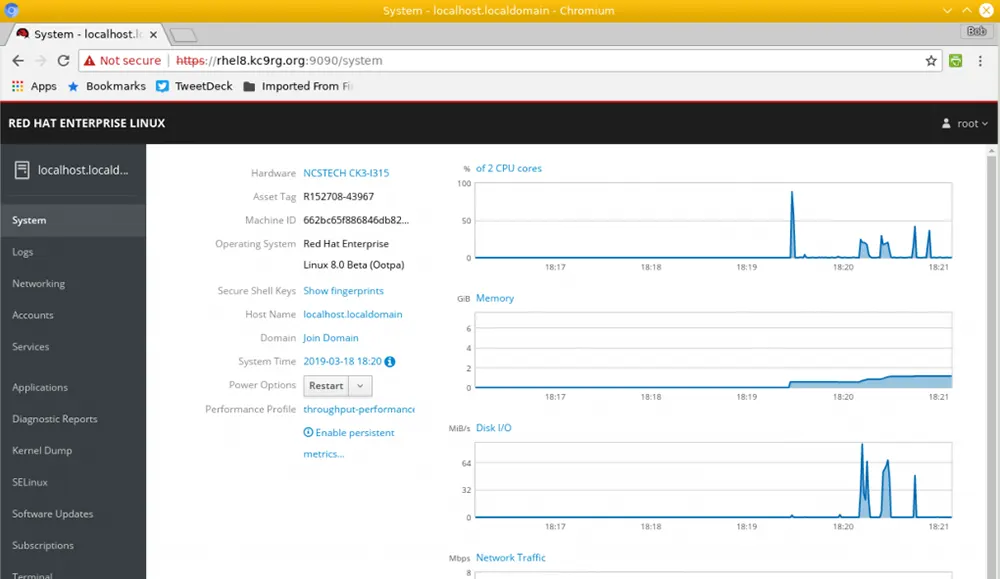
Linux and UNIXBob Cromwell
What's New in Red Hat Enterprise Linux 8?
-
Business Intelligence Microsoft OfficeLearning Tree International
Power BI: How to Save Memory for Better Performance
-
Cyber SecurityJohn McDermott
What Is Web Metadata Encryption and Why Is It Important?
-
Cyber SecurityJohn McDermott
WebAuthn: Toward the End of Passwords On the Web
-
Big Data & Data Science Business IntelligenceDan Buskirk
Turning Your AzureML Experiment into a Web Service
-
LeadershipRobert Annis
Change; Creating Your Competitive Environment
-
Project ManagementDavid Hinde
Playing Cards at Work: Planning Poker Estimating
-
Big Data & Data ScienceAndrew Tait
Defining the Data Puzzle: Data Science vs. Big Data vs. Data Analytics & More
-
Agile & Scrum Leadership Project ManagementRobert Annis
Management in an Agile world
-
Cloud Computing Communication Microsoft Office SharePoint Web DevelopmentMartyn Baker
Office 365: It's intuitive... Isn't it?
-
SandboxJohn McDermott
What is the New Windows Sandbox?
-
LeadershipLearning Tree International
The Women of Learning Tree: Lisa Bazlamit
-
LeadershipLearning Tree International
The Women of Learning Tree: Tricia Sacchetti
-
SQL ServerDan Buskirk
Batch Mode Processing for Row Data in SQL Server 2019
-
.NET/Visual StudioJohn McDermott
Cyber Security New Year's Resolutions for 2019
-
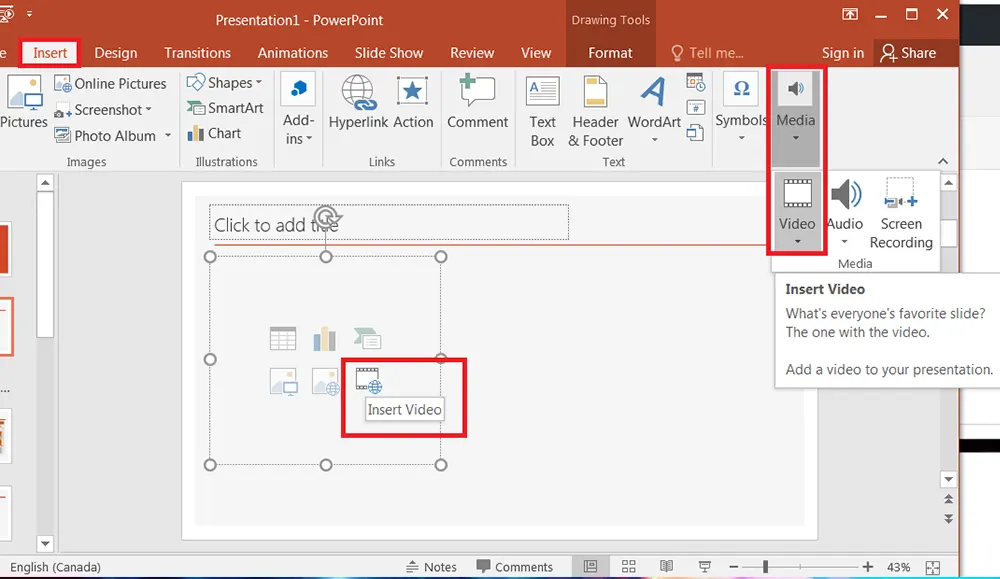
Microsoft OfficeArnold Villeneuve
Lights, Cameras, Action! Incorporate YouTube Videos In Your PowerPoint Presentation
-
Agile & Scrum Business AnalysisPeter Vogel
What is the Role of the Business Analyst in Agile?
-
SQL ServerDan Buskirk
UTF-8 Support in SQL Server 2019
-
Cyber SecurityJohn McDermott
URL Homograph Attacks Can Deceive Anyone
-
Big Data & Data Science Business Intelligence R ProgrammingDan Buskirk
Your Linear Regression Need Not Be Linear
-
Cyber SecurityJohn McDermott
Fraudsters Use Padlocks, Too: More on Certificate Use and Abuse
-
Microsoft OfficeArnold Villeneuve
Microsoft Office Compatible Productivity Tools on Your Mobile Phone or Tablet
-
Business Intelligence R ProgrammingDan Buskirk
Using .RProfile to Customize your R Environment
-
Cyber SecurityJohn McDermott
Medical Devices Still Aren't Secure
-
Business Intelligence Microsoft Office R ProgrammingDan Buskirk
Preparing SQL Data for R Visualizations Using Power Query Pivot
-
Cyber SecurityJohn McDermott
Beware of Online Extortion
-
Linux and UNIXBob Cromwell
Which Linux Training is Best for Programmers and Server Administrators?
-
.NET/Visual StudioNicole Fiorucci
No, I Am Not a Chatbot
-
Cyber SecurityJohn McDermott
More on Biometrics and Privacy
-
Microsoft Office Workforce Optimization SolutionsArnold Villeneuve
PowerPoint Keyboard Shortcuts to make you Shine
-
Cyber SecurityJohn McDermott
Information Leakage From Radio-Frequency Emissions
-
Microsoft Office Mobile App Development Workforce Optimization SolutionsArnold Villeneuve
PortableApps can save your Boss's conference presentation
-
Cyber SecurityJohn McDermott
How Should I Dispose of My Old Electronics (That May Have Passwords In Them)?
-
Linux and UNIXBob Cromwell
Which Linux Training Should I Select?
-
Cyber Security Training and DevelopmentJohn McDermott
What If Your Child's (Or Your) School Doesn't Teach Coding?
-
R ProgrammingDan Buskirk
Making Sense of Microsoft's RevoScaleR Function Parameters
-
Microsoft OfficeArnold Villeneuve
Using Microsoft Recorder to Create Documentation and Application Support Tickets
-
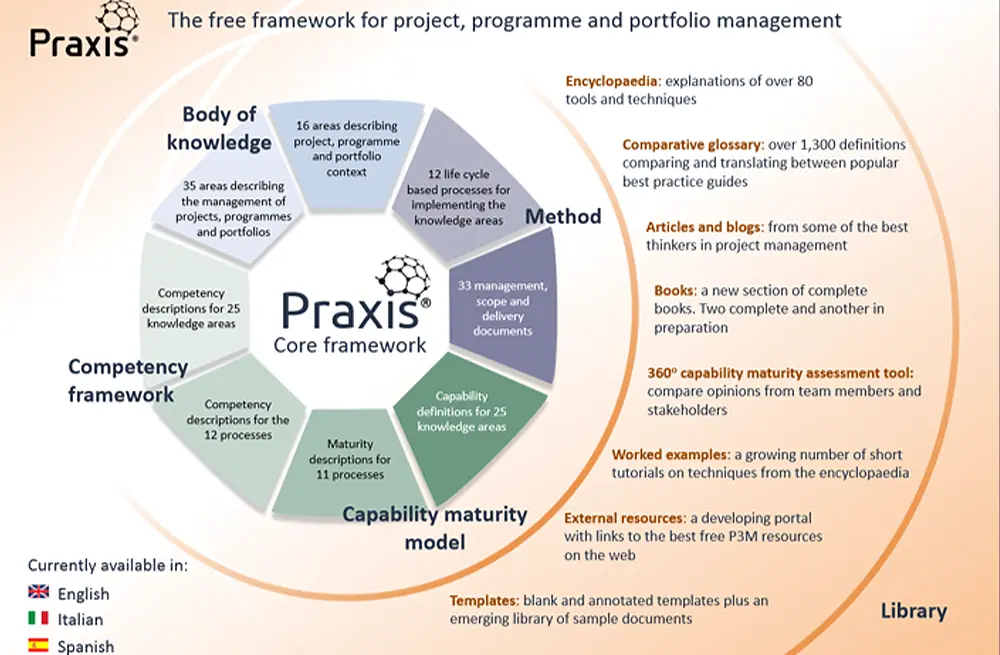
Project ManagementLearning Tree International
The Praxis Approach To Successful Projects & Programmes
-
COBIT(r) & TOGAF(r) ITIL(r) .NET/Visual StudioAlison Beadle
Getting Ready for ITIL 4, The Next Evolution of ITIL
-
Cloud Computing Cyber SecurityBob Cromwell
What Cybersecurity Threats Do We Face In The Cloud?
-
Cyber SecurityJoseph Danzer
MFA Challenges and What to Look for in a Solution
-
Cloud Computing Cyber SecurityBob Cromwell
What Are The Cybersecurity Challenges Associated With Cloud Computing?
-
Communication Cyber SecurityNicole Fiorucci
Customer Service: Avoid Falling Victim to Social Engineering
-
Cyber SecurityJohn McDermott
HTTPS Secures Site Traffic From Eavesdropping, But Who Can We Trust?
-
Cyber Security Networking & VirtualizationBob Cromwell
Manage Expectations to More Easily Pass Certification Exams
-
Cyber SecurityJohn McDermott
Lock The Door: Securing Your Home or Small Business Router
-
Cyber SecurityJohn McDermott
How Social Media Posts Can Lead to Identity Theft
-
Cyber SecurityJohn McDermott
No More Signatures! Am I Still Safe?
-
Web DevelopmentLearning Tree International
4 Reasons Why Python is a Great Language to Learn
-
Business Intelligence SQL ServerDan Buskirk
A Quick Binary Refresher for Analytic Query Writers
-
Blended TrainingLearning Tree International
Let's Build Something Great: The Future of Corporate Learning and Training
-
Web DevelopmentJohn McDermott
Is It a URI, a URL, Or Both?
-
.NET/Visual StudioRichard Spires
My "Top 10" Ways to Advance in IT Leadership
-
Training and DevelopmentJohn McDermott
Three More Keys to Successful Learning: Taking a Class and Continuing to Learn.
-
Cyber SecurityJohn McDermott
Data Theft Via the Cloud: You Don't Need Flash Drives Any More
-
Microsoft OfficeArnold Villeneuve
Customize your Office Ribbon and make it your own!
-
Cyber Security .NET/Visual StudioJohn McDermott
Leaving Your Mark: Thermal Signatures of Passwords Left on Keyboards
-
Big Data & Data Science Business Intelligence R ProgrammingDan Buskirk
Choosing a Machine Learning Platform That's Right for You
-
Cyber Security Web DevelopmentJohn McDermott
Defense in Depth: It's for Programmers, Too!
-
Big Data & Data Science .NET/Visual StudioAndrew Tait
Clustering data using k-means in ML.NET
-
Cyber SecurityJohn McDermott
Vishing: Another Way to go Phishing
-
Microsoft OfficePeter Vogel
Ten Steps to Creating Reliable Spreadsheets
-
Mobile App Development Web DevelopmentLori Gambrell
Utilizing Push Notifications in a Progressive Web App (PWA)
-
Training and DevelopmentJohn McDermott
A 5-step Learning Process to Encourage Learner Discovery
-
COBIT(r) & TOGAF(r) ITIL(r)Learning Tree International
ITSM practitioners and the need to improve skills
-
Cyber SecurityJohn McDermott
When Two-factor Authentication Goes Wrong
-
Big Data & Data ScienceImran Ahmad
Smart Data, not Big Data
-
Blended Training Training and DevelopmentLearning Tree International
"I Can't Get Anyone to Use It": A Corporate Training Tale
-
Big Data & Data Science .NET/Visual StudioAndrew Tait
ML.NET--an open source, cross-platform, machine learning framework for .NET
-
Blended Training Training and DevelopmentLearning Tree International
What is Blended Learning?
-
Big Data & Data Science Business IntelligenceDan Buskirk
Rise of the Cognitive APIs
-
Communication Microsoft OfficeArnold Villeneuve
How to Add Animation to Your PowerPoint Presentation
-
Communication Training and DevelopmentJohn McDermott
How Storytelling Helps Make a Personal Connection with an Audience
-
Big Data & Data ScienceLearning Tree International
The Importance of Always Learning
-
Cyber SecurityJohn McDermott
How Password Spraying Could be an Attack Vector Into Your Organization
-
Cyber SecurityJohn McDermott
What is a Stingray And How Does It Impact Me?
-
Agile & Scrum Business Analysis Project ManagementPeter Vogel
The Real Role of the Business Analyst: Connecting Strategy to Action
-
AWS AzureLearning Tree International
Azure vs. AWS: A Conversation with the Experts
-
Cyber SecurityBob Cromwell
Should I Become a Certified Ethical Hacker?
-
Agile & Scrum Project ManagementPeter Vogel
Actually, Project Managers are Pretty Good at Estimating Software Projects
-
Big Data & Data Science Business AnalysisImran Ahmad
Advanced Analytics in Professional Sports
-
Cyber SecurityJohn McDermott
Quad9 as a Tool to Fight Business Email Compromise
-
Networking & VirtualizationJohn McDermott
How the New WPA3 Can Improve Wi-Fi Security
-
SQL ServerDan Buskirk
The Advantages of Writing Stored Procedures
-
Cyber Security Training and DevelopmentJohn McDermott
Why a Certification is Only a Start
-
Agile & Scrum Project ManagementHamid Aougab
What the New PMBOK(r) Guide, Sixth Edition Means for the Future of Project Management
-
Cyber SecurityJohn McDermott
What is cyber security awareness, why should I care, and how do I get it?
-
Training and DevelopmentJohn McDermott
The Importance of Storytelling in Technical Training
-
LeadershipArnold Villeneuve
Upskilling for Administrative Professionals
-
Cyber SecurityLearning Tree International
Managing a Data Leak in your Business
-
SQL ServerDan Buskirk
Quick Guide to SQL Server Data Types
-
Business Analysis Communication Project ManagementJohn McDermott
How to Use Affinity Diagrams to Bring Order to Chaos
-
Agile & Scrum Business Analysis Project ManagementPeter Vogel
Getting Rid of Requirements
-
Training and DevelopmentJohn McDermott
Taking a Live Online Class: Keys to Success
-
Project ManagementAlison Beadle
How do you manage a project that follows the sun and never sleeps?
-
Communication SQL Server Training and DevelopmentPeter Vogel
The SQL Server Interview Questions that Matter
-
Cyber SecurityJohn McDermott
The Seriousness of the Cyber Security Staffing Shortage
-
Business Analysis COBIT(r) & TOGAF(r) ITIL Project ManagementAhmad Shuja
Introduction to Business Enterprises and IT Integration
-
Cyber SecurityJohn McDermott
Biometrics and Privacy
-
Web DevelopmentLearning Tree International
Making sense of React's different component styles
-
SharePointArnold Villeneuve
Implement a better performing and easier to management Microsoft SharePoint platform through solid permissions - Part 2
-
Cyber Security Networking & Virtualization SharePointArnold Villeneuve
Implement a better performing and easier to management Microsoft SharePoint platform through solid permissions - Part 1
-
Cybersecurity Encryption filesystems LinuxBob Cromwell
File System Encryption: When Is It Worthwhile?
















































![Learning Tree International Blog, "From Principles to People: Your guide to PRINCE2 7 [2024]"](https://cdn.buttercms.com/7lGj8n9xRrKuULI0Fx0M)