
With so many data integration solutions today, why should your organization consider Azure Data Factory Training?
There are many great reasons, including:
- Fully managed Azure service
- Code-free and low-code transformations
- Combination of GUI and scripting-based interfaces
- Easy migration from SSIS
- Consumption-based pricing
Let us explore each of these in more detail!
Fully managed Azure service
One significant challenge with traditional ETL/ELT tools is the deployment complexity. Organizations require teams of experts to install, configure and maintain data integration environments carefully. These experts could be in-house or external 3rd parties; it's an expensive proposition.
Microsoft fully manages Azure Data Factory as part of its Azure platform. Microsoft takes care of the Azure Integration Runtime (IR) that handles data movement, manages the Spark clusters that handle Mapping Data Flow transformations, regularly updates the ADF developer tools and APIs, and monitors the platform 24/7 across more than 25 regions to ensure peak performance.
All these activities take place without any involvement from us as customers. This allows us to focus on delivering value to our customers through the data integration workflows instead of getting side-tracked into time-consuming platform administration and maintenance.
Code-free and low-code transformations
The "T" in ETL and ELT stands for Transformation. Transformation is commonly the most challenging aspect of a data integration process. As a result, many enterprises have been developing custom scripts to deal with this step. The scripts could be written in SQL, Python, C# and many other industry standard and proprietary general-purpose programming languages or their data-centric variants.
Regardless of the language chosen, the challenge with all code-based approaches is maintenance complexity and the ease of inadvertently introducing bugs.
The former is due to developers having to be intimately familiar with the language to write efficient transformations. In addition, new developers must undergo extensive training. Each developer's unique coding style further complicates the onboarding process, a style others have to adjust to or a style the organization can try to standardize via coding conventions. Finally, there is a high risk of introducing bugs because real-world data transformation scripts often involve modules with tens of thousands or more lines of code. Every line represents a possible source of hidden, hard-to-find and hard-to-fix bugs.
ADF has two internal transformation technologies that can create transformations without a single line of code. Mapping Data Flows based on the industry-standard Apache Spark platform is one of these technologies. The second, currently in public preview and based on the proven Power Query / M engine, is Wrangling Data Flows,
With either technology, the ADF developer can rapidly create 100% code-free transformations or transformations primarily without code (aka "low-code"). Even expert programmers typically find it faster to use Mapping Data Flows or Wrangling Data Flows than to write code. Furthermore, Microsoft has meticulously optimized code-free and low-code transformations and thus performs the same or even better than manually crafted code that accomplishes the same result. Thus, the benefit here is much higher developer productivity, with corresponding bottom-line benefits to the organization.
Combination of GUI and scripting-based interfaces
The other challenge familiar with enterprise ETL/ELT platforms is that they lock their users into specific and often very proprietary tools. These tools were typically either UI-based or scripting-based, with no practical ability for the user to switch between different tools during the DevOps lifecycle. Also, the UI-based tools were typically implemented as platform-native applications (ex., Windows, Linux, Mac OS, etc.) and brought in complex installation and upgrade requirements.
With ADF, the Microsoft team took a different approach. It created a standard HTML5 development environment at https://adf.azure.com. This environment needs only a current web browser to access. Yet it maintains the look and feel of a traditional platform-native GUI application. For example, you can easily drag and arrange activities into a data integration pipeline. Moreover, the interface is so impressively implemented that developers often forget they are interacting with a web browser.
A variety of other interface types are available for scripting and automation purposes. These include PowerShell, REST API - direct and via SDKs, and Azure Resource Manager (ARM) Templates. PowerShell has been around for many years and is used on Windows, Mac OS and Linux for all types of automation. Its Azure version is even available via Azure Cloud Shell. REST API opens up many additional integration possibilities. .NET and Python can call higher-level SDKs that these APIs expose. Other platforms can consume the APIs directly. And finally, ARM Templates are perfect for declarative integration, such as replicating consistent configurations and thus avoiding configuration drift.

Easy migration from SSIS
SQL Server Integration Services (SSIS) was introduced into the SQL Server stack back in 2005. Technology has proven hugely popular over the years. As a result, organizations have invested millions of dollars into creating SSIS data integration packages for their specific requirements.
Microsoft has considered this and provided a way to migrate SSIS packages into ADF while taking full advantage of Azure and ADF's Platform as a Service (PaaS) paradigm. In other words, one must no longer create and manage a SQL Server VM with ADF just to run SSIS.
How does this work? The magic ingredient is the Azure-SSIS Integration Runtime (IR).
Like the central Azure IR, the Azure-SSIS runtime is entirely operated by the Azure team. However, instead of using the new ADF technology for the data integration pipelines and activities, it runs existing SSIS packages. These packages can use the newer SSISDB catalog deployment option (introduced in SQL Server 2012) and the original SSIS package-level deployment option. As a result, the packages can typically remain 100% the same as before or at least stay remarkably close to this state — additionally, your existing tools, such as SSDT, SSMS and duties.
Taking advantage of Azure-SSIS IR gives you the best of both worlds: a fully managed runtime environment on Azure plus the ability to retain your existing SSIS packages, tools and processes.
Consumption-based pricing
The ETL/ELT tools have historically had high licensing costs. These costs usually had to be paid upfront. This might have been fine on large, entirely predictable, multi-year efforts. However, the reality today is that change is often unpredictable, and organizations must adapt rapidly, in an agile manner, run short POCs, "fail-fast," etc.
These business and IT goals are inconsistent with large up-front license purchases. The other cost-related challenge with traditional licensing approaches is that organizations would almost always be over or under. With over-provisioning, they would be paying too much for licenses, just in case - ex., to handle workload peaks. With under-provisioned, they would be saving money but experiencing slow performance during workload peaks.
The utility-type consumption-based pricing in Azure is much better suited to this new business and IT operating environment. In addition, with Azure Data Factory, there are zero upfront costs, while performance is always optimal.
Ongoing costs with ADF are segmented into two main areas: development and pipeline execution/runtime.
The development costs primarily consist of data factory storage. If you use Mapping Data Flows, you would also be paying for debugging Spark clusters. Both ingredients are typically reasonably minor, although Spark clusters' costs need a little care to minimize (ADF provides controls such as TTL to facilitate this). Importantly, unlike Visual Studio, which has paid Professional and Enterprise editions, there is zero cost to using any ADF development tools.
Pipeline execution / runtime costs are tied to the complexity and volume of data integration workflows. Pricing is elastic and automatically adjusts to workloads. There is no need to pre-pay, predict, estimate or otherwise tune licensing.
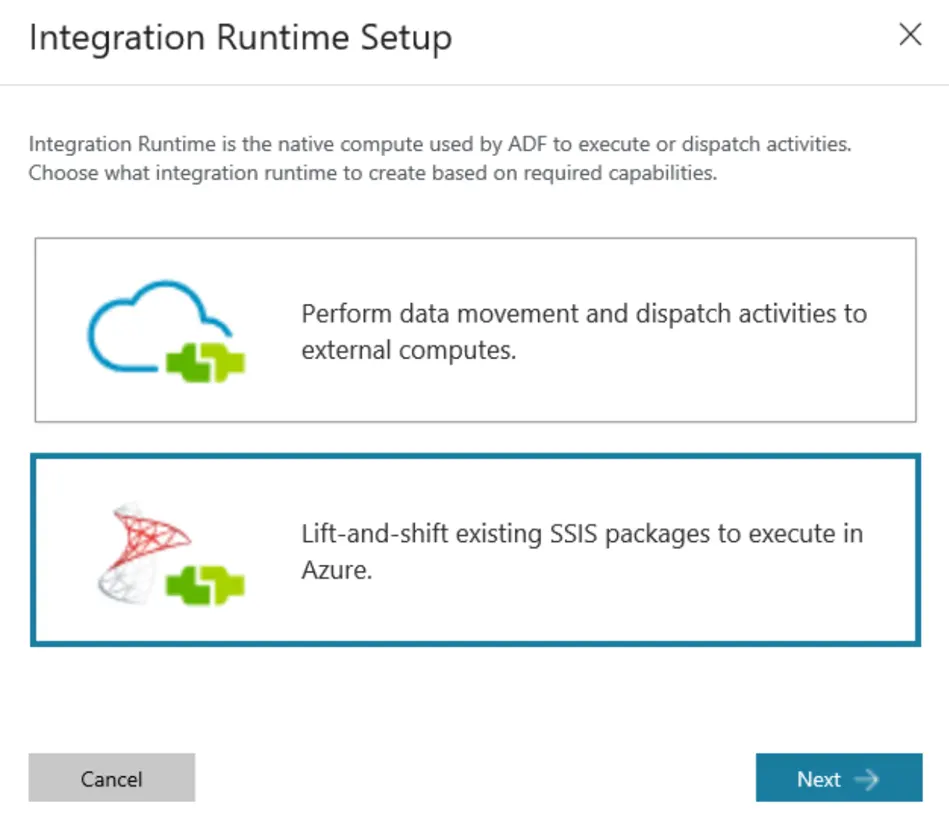
The ADF team created a metric that simplifies pricing calculations called Data Integration Unit (DUI). Execution costs are calculated based on the number of DUIs consumed by the pipeline(s) at runtime. Azure-SSIS runtime uses different pricing but also ties to complexity/unit-of-time concepts.
The result is transparent, easy-to-understand pricing that minimizes up-front license purchase risk and dynamically adapts to your workload requirements.
This piece was originally posted on November 4, 2020, and has been refreshed with updated styling.